前言
御剑这个工具想必大家都听说并使用过,C段、旁注、批量注入、后台扫描、MD5解密、编码转换等等,功能很强大。特别是在寻找网站敏感文件目录方面,用个大一点的字典跑啊跑,一会就跑出了很多东西。今天试着用 Python 写了一个有类似扫描功能的小脚本,在这里记录一下过程。代码写的比较烂,实用性也不大,目的仅在于锻炼自己的编程能力,同时也给想学习 Python 的童鞋做个参考。我会写出自己的思考过程,方便大家理解。
过程
首先思考要实现的功能。我们想写一个判断 URL 是否存在的小工具,所以就要不断的穷举网站的 URL ,通过返回的状态码来判断页面是否存在,状态码为 200 则说明页面存在,如果是 404 则说明页面不存在,其他如 403、500 等说明存在但无权限或服务器出现错误。所以这里要使用写爬虫时会用到的 urllib2 模块,但是我们不用抓取页面内容,只需要尝试打开页面就好。为了方便,还需要将爆破的域名和要使用的字典以参数的形式传入到程序,所以还要用到 argparse 模块。
有个大概的思路就可以了,下面开始码代码。
导入要使用的模块,urllib2和argparse
urllib2 模块是 Python 的一个获取 URLs 的组件。它以 urlopen 函数的形式提供了一个非常简单的接口,具有利用不同协议获取 URLs 的能力。而 argparse ,它是 Python 编写命令行程序的工具,由于 optparse 在 Python2.7 版本之后就停止开发了,所以 Python 标准库中推荐使用 argparse。
import urllib2 import argparse
首先定义一个 ScanUrl 函数,用来处理传入的 URL 。
def ScanUrl(url):
req = urllib2.Request(url)
try:
result = urllib2.urlopen(req,timeout=2)
print '[+]200 found the Url : %s' % url
#捕获urlopen无法解决的错误
except urllib2.HTTPError,e:
if e.code in [401,403,500,503]:
print ('[*] Notice : ' + str(e) + ' : ' + url)
else:
pass
#捕获其他错误
except Exception,e:
print str(e)
exit(0)
#测试一下函数是否正常使用,以我的博客为例。
ScanUrl('http://blog.jenisec.org/index.html')
[+]200 found the Url : http://blog.jenisec.org/index.html
我们使用 urlopen 方法打开传入的 URL ,如果正常打开,就打印一条消息指明这个 URL 是存在的,如果捕获到的状态码为401、403、500、503,也同样打印一条信息,提示存在,但有错误。如果捕获到其他错误,将错误打印出来。
再定义一个 Geturl 函数,用来处理传入的域名和字典文件。
def Geturl(host,dicfile):
try:
f = open(dicfile,'r')
for line in f.readlines():
url = host + line.strip('\r\n')
ScanUrl(url)
f.close()
except Exception,e:
print('[-]Error : ' + str(e))
exit(0)
Geturl 接受两个参数,其中 host 为用户输入的域名,dicfile 为字典文件,我们用读的方式打开字典文件,循环取出每一行的内容,将它拼接在域名后面,组成一个完整的 URL ,然后调用 ScanUrl() 函数去处理得到的 URL 。字典文件内容格式如下:
/phpmyadmin/db_create.php
/intraAdmin/admin.php
/do/reg.php
/tag.php
/wp-admin/install.php
/wp-admin/admin-ajax.php
/Html/fckeditor/fckeditor.php
/admin/admin.php
/admin.php
/SEM_User/admin_php/login.php
/admin/index.php
/admin/login.php
/manager.php
/login.php
/guestbook/admin.php
/blog/admin.php
/ask/admin.php
/add.php
.
.
.
接下来定义一个 main 函数,用来接受命令行传入的参数。
def main():
parser = argparse.ArgumentParser()
parser.add_argument("-H","--host",type=str,help="specify target host")
parser.add_argument("-d","--dic",type=str,help="specify target dicfile")
args = parser.parse_args()
host = args.host
dicfile = args.dic
if host == None or dicfile == None:
print ('usage : urlscan.py -H <target host> -d <dicfile>')
exit(0)
Geturl(host,dicfile)
if __name__ == '__main__':
main()
上面的代码创建了一个 parser ,使用 add_argument() 方法设置程序可接受的命令行参数,最后调用 parse_args() 方法进行解析。
将文件保存为 urlscan.py ,以百度为例,然后在终端执行
python2 urlscan.py -H https://www.baidu.com -d php.txt
不出意外,应该会得到以下信息
[+]200 found the Url : https://www.baidu.com/phpmyadmin/db_create.php
[+]200 found the Url : https://www.baidu.com/intraAdmin/admin.php
[+]200 found the Url : https://www.baidu.com/do/reg.php
[+]200 found the Url : https://www.baidu.com/tag.php
[+]200 found the Url : https://www.baidu.com/wp-admin/install.php
[+]200 found the Url : https://www.baidu.com/wp-admin/admin-ajax.php
.
.
.
你会发现所有的地址全部都是200,但是以我的博客作为目标时又是正常的,这是为什么呢?
我们随便打开一个上面提示存在的页面,看看有什么效果。结果是当我们访问一个不存在的页面时,网页被重定向到了其他页面,由于 urllib2 会自动处理 301、302 等状态码,所以我们的脚本得到的状态码始终是重定向之后的 200。
找到原因了,那就改写脚本,我们不使用 urlopen 方式打开网页,而是使用我们自己创建的 opener 打开。首先定义 HTTPRedirectHandler 类:
class RedirctHandler(urllib2.HTTPRedirectHandler):
def http_error_301(self, req, fp, code, msg, headers):
pass
def http_error_302(self, req, fp, code, msg, headers):
pass
改写 ScanUrl() 函数,创建 opener ,并使用它打开 URL
def ScanUrl(url):
req = urllib2.Request(url)
opener = urllib2.build_opener(RedirctHandler)
try:
result = opener.open(req,timeout=2)
print '[+]200 found the Url : %s' % url
except urllib2.HTTPError,e:
if e.code in [401,403,500,503]:
print ('[*] Notice : ' + str(e) + ' : ' + url)
else:
pass
except Exception,e:
print str(e)
exit(0)
opener.close()
这时在遇到重定向的网页时就会直接跳过,而不会再把所有页面都视作存在了。
脚本效果如下:
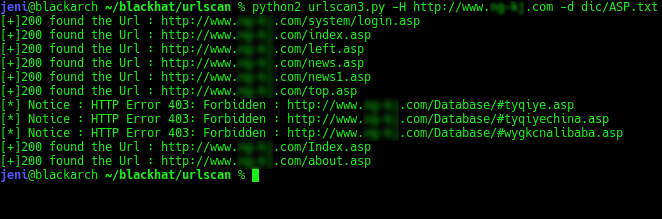
现在效果已经出来了,但是还有一个问题,现在的脚本在执行时是单线程,速度太慢了,如果可以改成多线程肯定可以节省很多时间。多线程的话要再引入一个 threading 模块
import threading
修改 Geturl() 函数的迭代,引入多线程,把每一个 ScanUrl() 函数当做一个线程
def Geturl(host,dicfile):
try:
f = open(dicfile,'r')
for line in f.readlines():
url = host + line.strip('\r\n')
t = threading.Thread(target=ScanUrl,args=(url,))
t.start()
f.close()
except Exception,e:
print('[-]Error : ' + str(e))
exit(0)
这里需要注意一下,threading.Thread() 内的 args 参数为一个元组,只传了一个值时要加一个逗号
现在再执行脚本就是以多线程方式运行了,执行速度大大的提升了
最后附上完整的代码
#!/usr/bin/env python2 # -*- coding=UTF-8 -*-import urllib2 import argparse import threading
class RedirctHandler(urllib2.HTTPRedirectHandler): def http_error_301(self, req, fp, code, msg, headers): pass def http_error_302(self, req, fp, code, msg, headers): pass
def ScanUrl(url): req = urllib2.Request(url) opener = urllib2.build_opener(RedirctHandler) try: result = opener.open(req,timeout=2) print '[+]200 found the Url : %s' % url except urllib2.HTTPError,e: if e.code in [401,403,500,503]: print ('[*] Notice : ' + str(e) + ' : ' + url) else: pass except Exception,e: print str(e) exit(0) opener.close()
def Geturl(host,dicfile): try: f = open(dicfile,'r') for line in f.readlines(): url = host + line.strip('\r\n') t = threading.Thread(target=ScanUrl,args=(url,)) t.start() f.close() except Exception,e: print('[-]Error : ' + str(e)) exit(0)
def main(): parser = argparse.ArgumentParser() parser.add_argument("-H","--host",type=str,help="specify target host") parser.add_argument("-d","--dic",type=str,help="specify target dicfile") args = parser.parse_args() host = args.host dicfile = args.dic if host == None or dicfile == None: print ('usage : urlscan.py -H <target host> -d <dicfile>) exit(0) Geturl(host,dicfile)
if __name__ == '__main__': main()
作者: JenI 转载请注明出处,谢谢
Comments !