前言
逆向工程,英文是reverse_engineering,是一种根据已有的东西推导出具体实现方法的技术。在计算机领域,逆向工程常用于挖掘漏洞、分析病毒、破解软件、制作游戏辅助等。而汇编语言作为所有高级语言的基础,对于逆向工程来说更是必不可少的一部分,因此,学习 CPU 工作原理和汇编语言通常是掌握逆向工程技术的第一步。下面是我整理的一些关于 Win32 反汇编的基础知识。
Win32 反汇编基础
一、十六进制
十进制是我们平时最常用的进制,用数字 0-9 表示每一个元素,而十六进制,它是在十进制的基础上,增加了 A,B,C,D,E,F 六个元素,用以代表十进制中的 10,11,12,13,14,15。十六进制,顾名思义,逢十六进一。下面是几个简单的例子:
- 9 + 1 = A (十进制的 10)
- F + 1 = 10 (十进制的 16)
- A + B = 15 (十进制的 21)
- FF + 1 = 100 (十进制的 256)
为了区别不同进制的同一数字,十六进制一般会在数字前加 0x,如 0x123,或在末尾加 H,如 123H
十六进制的负数通常使用补码的方式表示,所谓补码即它本身的值按位取反,最后再加一,例如 -3 的十六进制表示方式为 0x00000003 取反 0xFFFFFFFC 再加一,最终等于 0xFFFFFFFD
二、内存单元长度修饰
-
BIT(位): 在计算机中,由于只有逻辑 0 和逻辑 1 的存在,所以所有的操作、数据等最终都会表示为一串二进制的字码。其中,每个逻辑 0 或者 1 便是一个位,它是计算机中最基本的单位
-
BYTE(字节)(C 语言中的 unsigned char 类型): 8 个位表示为一个字节,所以一个字节的范围二进制为 00000000-11111111,十进制表示为 0-255。而汇编中通常表示为 16 进制,范围 0-0xFF
-
WORD(字)(C 语言中的 unsigned short 类型): 一个字由两个字节组成,共有 16 位。十进制范围 0-65535,十六进制范围 0-0xFFFF
-
DWORD(双字)(C 语言中的 unsigned int 类型): 一个双字包含两个字,即 4 个字节,共有 32 位。十进制范围 0-4294967295(4G),十六进制范围 0-0xFFFFFFFF
三、寄存器
寄存器是 CPU 内重要的组成部分,用于暂存指令、数据和地址。Intel x86 CPU 中,有如下寄存器
1. 通用寄存器(32 位,8 个)
- EAX: 累加器
- EBX: 基址寄存器
- ECX: 计数器
- EDX: 数据寄存器
- ESI: 源变址寄存器
- EDI: 目的变址寄存器
- EBP: 扩展基址指针寄存器
- ESP: 栈指针寄存器
这些通用寄存器由 IA-16 的 16 位扩展而来,因此使用 "E"+原16位寄存器名 的方式表示,如 AX => EAX。为了实现对低 16 位的兼容,各寄存器又可以分为高(H:High)、低(L:Low)几个独立寄存器,如 EAX 可表示为:
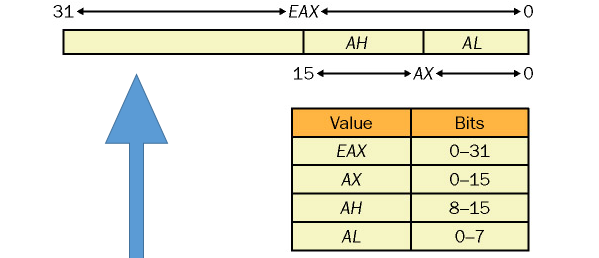
如图所示,EAX 低 16 位可用 AX 表示,AX 的高 8 位表示为 AH,低 8 位表示为 AL,这些寄存器都可以被独立使用
2. 段寄存器(16 位,6 个)
- CS(code segment): 代码段寄存器,用于存放应用程序代码所在段的段基址
- DS(data segment): 数据段寄存器,用于存放数据段的段基址
- ES(extra segment): 附加段寄存器,用于存放程序使用的附加数据段的基地址
- SS(stack segment): 栈段寄存器,用于存放栈段的段基址
- FS(data segment): 数据段寄存器
- GS(data segment): 数据段寄存器
3. 程序状态与控制寄存器(32 位,1 个)
EFLAGS: 标志寄存器,EFLAGS 共 32 位,每一位都有意义,其值为 0(False) 或 1(True)。
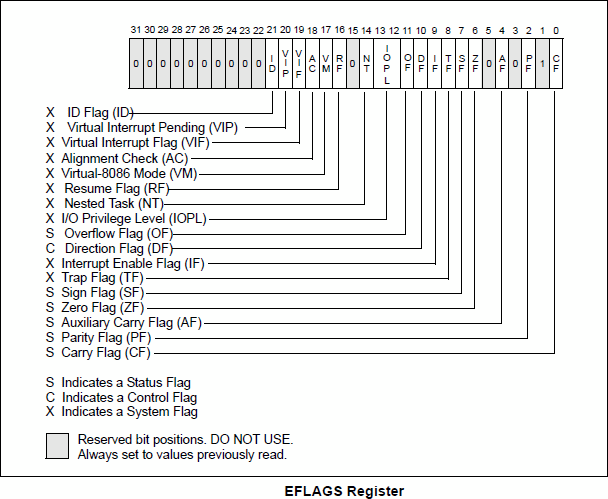
这些标志位的值大部分由系统指定,而可能受到指令或计算影响的标志位则会在调试工具中被展示,例如 OD 中就对下列标志位进行了直观的展示,其中 ZF、OF、CF,这三个标志位在逆向过程中最为重要,因为其可能影响了程序运行过程中的执行逻辑。
- CF(进位标志位): 当执行一个加法或减法运算时,最高位产生进位或借位时,CF 值将被置为 1,否则为 0
- ZF(零标志位): 若当前运算结果为 0,则 ZF 为 1,否则为 0
- SF(符号标志位): 该标志位与运算结果的最高位相同。即运算结果为负,则 SF 为 1,否则 SF 为 0
-
OF(溢出标志位): 若运算结果超出机器能够表示的范围则会溢出,此时 OF 为 1,否则为 0。
判断溢出的方法: 进行二进制运算时,最高位的进位与次高位的进位值进行异或运算,若运算结果为 1,则表示溢出,OF=1,否则 OF=0
(1).同号相加和异号相减才可能发生溢出;
(2).同号相加结果的符号与参与运算的符号不同就溢出;
(3).异号相减结果的符号位与被减数的符号位不同就产生溢出; -
PF(奇偶标志位): 当运算结果的最低 16 位中含 1 的个数为偶数则 PF=1,否则 PF=0
- AF(辅助进位标志): 一个加法或减法运算结果的低 4 位向高 4 位有进位或借位时 AF=1,否则 AF=0
- TF(跟踪标志位): 该标志位为方便程序调试而设计,若 TF=1,CPU 处于单步工作方式,即在每条指令执行结束后,产生中断
- IF(中断标志位): 该标志位用来控制 CPU 是否响应可屏蔽中断,若 IF=1,则运行中断,否则禁止中断
- DF(方向标志位): 该标志位用来控制字符串处理指令的处理方向,若 DF=1,则字符串处理过程中自动递减,否则自动递增
4. 指令指针寄存器(32 位,1 个)
- EIP: 指令指针寄存器: EIP 内保存着CPU要执行的下一条指令地址。程序运行时,CPU 会读取 EIP 中的指令地址,将指令传送到指令缓冲区后,EIP 寄存器的值会自动增加,增加大小为读取指令的字节大小
5. 浮点寄存器(80 位,8 个)
- ST0-ST7: 浮点寄存器是两用寄存器,当使用 ST0-ST7 表示时,这八个寄存器又称浮点运算单元(Float Point Unit, FPU),专门用来做浮点数运算。当使用 MM0-MM7 表示时,用来处理多媒体数据,如语音、图像、视频等。
四、字节序
字节序表示多字节数据在计算机内存中存储或网络传输时各字节的存储顺序,主要分为小端序和大端序两类。
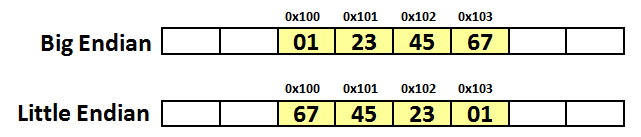
如图所示,如果采用大端序存储数据,内存地址的低位存储数据的高位,内存地址的高位存储数据的低位,即高位低地址,低位高地址。而采用小端序存储数据的话,内存地址的低位存储数据的低位,内存地址的高位存储数据的高位,即高位高地址,低位低地址。需要注意的是,字节型的数据其长度本身为一个字节,因此在存储这样的数据时,采用大端序和小端序的字节顺序都是一样的。char[] 类型的字符数组在内存中是连续的,所以存入此字符数组的的数据,顺序也是一样的,如下图所示:

五、栈
栈通常用于存储局部变量、传递函数参数、保存函数返回地址等,它按照后进先出的原则存储数据
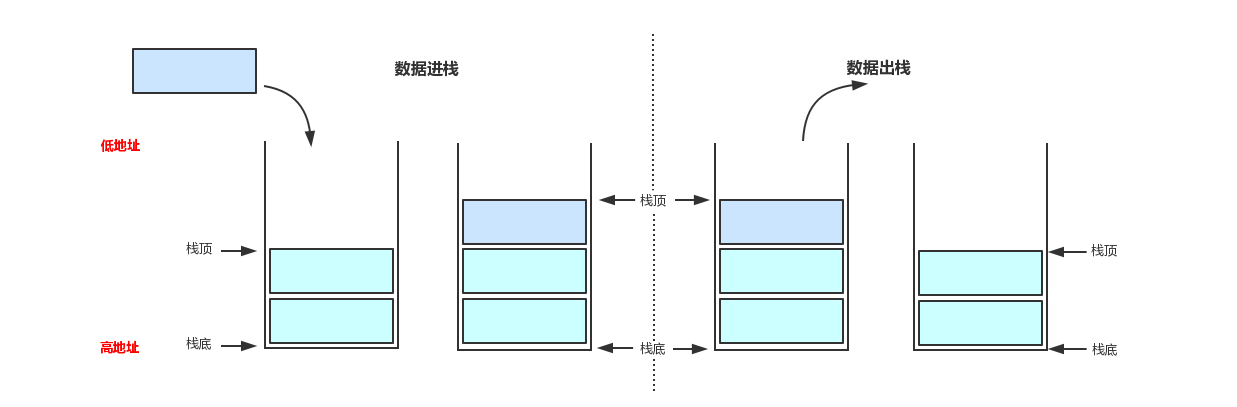
在一个进程中,初始的栈顶指针(ESP)指向栈的栈底位置。执行 PUSH 指令将数据压入栈时,栈顶指针就会上移到栈顶位置。执行 POP 指令将数据弹出栈时,栈顶位置下降,栈顶指针也就随之下移。也就是说,栈顶指针始终指向一个数据栈的栈顶位置。而对于一个栈而言,栈底位置属于内存空间中的高地址,因此在向栈中压入数据时,栈顶指针向上(低地址)移动,ESP 减小,从栈中弹出数据时,栈顶指针向下(高地址)移动,ESP 增加。
六、常用汇编指令
-
MOV 传送指令: 用于将源数赋值给目的数
语法: MOV 目的数, 源数
变形 1: MOVS/MOVSB/MOVSW/MOVSD EDI, ESI (将 ESI 指向的内容传送到 EDI 中,其中 B、W、D 分别指 BYTE、WORD、DWORD,用于修饰所传送的数据长度)
变形 2: MOVSX (符号扩展传送,将单字或者单字节扩展为双字或者双字节传送,原符号不变)
变形 3: MOVZX (零扩展传送,扩展单字节或单字为双字节或双字并且用 0 填充剩余部分)
MOVSX 和 MOVZX 语法格式与 MOV 相同,但是这两个指令要求源数的操作空间必须小于操作数 A,比如: MOVSX/MOVZX EAX, AX。另外一点需要注意的是,MOV 指令为原值传送,传送后数值不会发生改变,而 MOVSX 和 MOVZX 都有可能会改变原值。 -
ADD 加法指令: 将一个数值加在一个寄存器上或者一个内存地址上,结果影响 ZF、OF、CF 标志位
语法: ADD 目的数,源数
使用高级语言表示为 目的数 = 目的数 + 源数 -
SUB 减法指令: 将一个寄存器或者一个内存地址的数值减去一个数值,结果影响 ZF、OF、CF 标志位
语法: SUB 目的数,源数
使用高级语言表示为 目的数 = 目的数 - 源数 -
IMUL 有符号乘法: 结果可能影响 OF、CF
语法 1: IMUL 数值 - 数值乘以 AL、AX 或 EAX 寄存器(取决于数值大小)中的值,乘积分别存储到 AX、AX/DX 或 EAX/EDX 寄存器
语法 2: IMUL 目标寄存器, 数值 - 目标寄存器中的值乘以数值,乘积存储到目标存储器
语法 3: IMUL 目标寄存器, 数值, 数值 - 两个数值相乘,乘积存储到目标存储器 -
MUL 无符号乘法: MUL 指令同 IMUL 指令相同,不过 MUL 指令可以乘无符号数
语法 1: IMUL 数值 - 数值乘以 AL、AX 或 EAX 寄存器(取决于数值大小)中的值,乘积分别存储到 AX、AX/DX 或 EAX/EDX 寄存器
语法 2: IMUL 目标寄存器, 数值 - 目标寄存器中的值乘以数值,乘积存储到目标存储器
语法 3: IMUL 目标寄存器, 数值, 数值 - 两个数值相乘,乘积存储到目标存储器 -
IDIV 有符号除法: 用来将 EAX 除以除数(有符号除法),被除数通常是 EAX,结果也储存在 EAX 中,而被除数对除数取的模最终存在除数中。
语法: IDIV 除数 -
DIV 无符号除法: DIV 指令同 IDIV 指令相同,不过 DIV 是无符号的除法
语法: DIV 除数 -
PUSH 入栈指令: 用于将数据压入栈
语法: PUSH 操作数(操作数可以是寄存器,存储器,或者立即数)
等价于顺序执行下面的两条命令SUB ESP, 4
MOV [ESP], EBP -
POP 出栈指令:
语法: POP 操作数(操作数可以是寄存器,存储器,或者立即数)
等价于顺序执行下面的两条命令MOV EBP, [ESP]
ADD ESP, 4 -
AND、OR、SETE、SETNE、XOR
OR 或运算 :
逻辑或(C 中的 ||): 全假为假,有真则为真。(截断原理: 将更大可能性为真的条件放在或的前面,则可以在验证完第一个条件后直接结束判断,因为只要前面的条件为真,后面的条件不管是否为真,最终结果都为真)。OR 指令会清空 OF、CF 标志位,设置 ZF 标志位
按位或(C 中的 |): 每一个 bit 位做或运算,如 00110011 和 01100110 做按位或,结果为 01110111
与运算 :
逻辑与(C 中的 &&): 全真为真,有假则为假。也遵循截断原理(将更大可能性为假的条件放在前面)
按位与(C 中的 &): 每一个 bit 位做与运算,如 00110011 和 01100110 做按位与,结果为 00100010
非运算 :
逻辑取反(C 中的 !): 假变真,真变假,通过 ZF 标志位的值来确定
SETE/SETNE : 取 ZF 标志位的值保存/取 ZF 标志位取反的值保存
按位取反(C 中的 ~): 每一个 bit 位取反,如 00110011 取反后,结果为 11001100,指令为 NOT
XOR 异或运算 :
按位异或,相当于 C 中的 ^,相同为 0,不同为 1。比如 1101 ^ 0110 = 1011
异或常用于将寄存器清零,如 XOR EAX, EAX -
浮点运算: 浮点寄存器和栈类似,使用浮点运算指令向寄存器存入数据时,数据首先被存入 ST0,当再次执行存入指令时,原 ST0 中的值被存入 ST1,新的值存入 ST0。数值被取出时也按照 ST0-ST7 的顺序,所以说和栈的先进后出原则相似
FLD : 相当于 PUSH 指令,将一个浮点数存入 ST0
FSTP : 相当于 POP 指令,将 ST0 中的浮点数取出
FADD : 相当于 ADD 指令,浮点数的加法指令,但语法格式略有区别,因为运行浮点数指令时数值会自动从浮点寄存器中取出,因此浮点运算指令后只加内存地址就可以了,下面的指令也是这样
FSUB : 相当于 SUB 指令,浮点数的减法指令
FMUL : 相当于 SUB 指令,浮点数的乘法指令
FDIV : 相当于 SUB 指令,浮点数的除法指令
FILD : 整数转浮点指令,将一个整数转为浮点数后存入 ST0
CVTTSD2SI : 浮点数转整数指令,运用截断处理将 ST0 中的单精度浮点数转换成 r32 中一个有符号的双字整数(Intel CPU 针对 C++ 程序有一个 AND 指令的优化对齐操作,通过对齐 8 的边界上的指针从而加速数据处理速度,牺牲空间,节约时间) -
CALL 函数调用: 将当前 CPU 要执行的下一条指令地址(即 IP)压入栈,然后跳转到 CALL 指令指定的子程序处执行。
语法: CALL 操作数(操作数可以是寄存器,偏移地址,或者立即数)
CALL 指令分为两种情况,一种是段内转移,另一种是段间转移。一个段内转移的 CALL 指令等价于顺序执行下面的两条指令PUSH EIP
JMP 目的地址
-
PUSH CS
PUSH EIP
JMP 目的地址
-
RET 返回指令: 从子程序中退出到调用它的 CALL 指令处,此时栈中保存的 EIP 和 CS 值弹出,重新赋值给 EIP 和 CS 寄存器
-
CMP 比较指令: 用于比较两个值的大小,实际上是对两个值进行了减法操作,结果影响 ZF、OF、CF 标志位,但是并不会对计算结果进行储存
语法: CMP 操作数1, 操作数2
CMP 指令主要用于配合条件转移指令使用,如 JZ/JE 等命令 -
TEST
TEST 指令通常用于判断寄存器是否为 0,它和 AND 有相同的功能,但是不储存结果,仅改变 ZF 标志位的值,寄存器为 0 则将 ZF 标志位置为 1,寄存器不为 0 则将 ZF 标志位置为 0 -
JUMPS 条件转移指令: 根据指令的不同,对指定标志位进行判断,满足条件则跳转(其中 E(equal)/Z(zero)等价,属于同一指令的两种助记符,均判断 ZF 标志位是否为 1)
语法: 指令 地址JMP 地址: 无条件跳转,直接跳转到指定地址处,相当于 C 中的 GOTO 命令
JE/JZ 地址: ZF = 1 时,跳转到指定地址处
JNE/JNZ 地址: ZF = 0 时,跳转到指定地址处
JL/JNGE 地址: SF != OF 时,小于/不大于等于则跳转到指定地址处(有符号)
JLE/JNG 地址: ZF = 1 and SF != OF 时,小于等于/不大于则跳转到指定地址处(有符号)
JG/JNLE 地址: ZF = 0 and SF = OF 时,大于/不小于等于则跳转到指定地址处(有符号)
JA/JNBE 地址: CF = 0 and ZF = 0 时,高于/不低于等于则跳转到指定地址处(无符号)
JNB/JAE/JNC 地址: CF = 0 时,不低于/高于或等于/CF未被标记(无进位)则跳转到指定地址处(无符号)
JB/JNAE/JC 地址: CF = 1 时,低于/不高于等于/CF被标记(有进位)则跳转到指定地址处(无符号)
JBE/JNA 地址: CF = 1 or ZF = 1,低于或等于/不高于则跳转到指定地址处(无符号) -
INC、DEC
语法: INC/DEC 操作数
相当于 ADD/SUB 指令的 +1/-1 操作,等价于 C 中的 i++、++i / i--、--i。虽然和加减一操作的结果相同,但是 INC/DEC 相较于 ADD/SUB 指令来说,速度更快,占用空间更小。自增自减命令结果会影响 AF、CF、PF、SF、ZF 标志位,但是不影响 CF 进位标志位 -
LEA 有效地址传送指令
语法: LEA 目的数、源数
LEA 用于取偏移地址,例如 LEA AX,[1000H],作用是将源数 [1000H] 的偏移地址 1000H 送至 AX。理解时,可直接将[ ]去掉,等同于 MOV AX,1000H -
NOP 空指令
NOP 指令表示不做任何事,常用于逆向过程中改变程序执行逻辑,将某些指令移除 -
循环控制指令: 使用 ECX 寄存器作为计数器,来控制程序的循环,每次循环 ECX 减 1,如果 ECX != 0,则跳转回标号处执行
语法: LOOP 标号 -
位移指令
SHR 逻辑右移指令 : 右移一位相当于整除 2,用 0 来补位
SHL 逻辑左移指令 : 左移一位相当于乘以 2,用 0 来补位(可能会有溢出)
SAR 算术右移指令 : 右移时保留操作数的符号,即用符号位来补足
SAL 算术左移指令 : 功能和 SHL 完全相同
ROL 循环左移指令
ROR 循环右移指令 -
串比较相关指令
SCASB/SCASW/SCASD 串比较指令 : 将 AL 或 AX 中的内容与目标串最比较,编译后显示为 SCAS BYTE PTR ES:[EDI],指令效果相当于 CMP BYTE PTR [EDI], AL
SCASB 指令对标志位的影响相当于 SUB 指令,同时还会修改寄存器 EDI 的值,如果 DF 标志位为 0,则 INC EDI,如果标志位为 1,则 DEC EDI
REPNE/REPNZ 连续执行指令 : 当 ECX!=0 并且 ZF=0 时,重复执行后边的指令,每执行一次 ECX 减 1
结合使用: REPNZ SCASB 编译后表示为 REPNE SCAS BYTE PTR ES:[EID],当 ECX!=0 且对应串元素不相同(ZF=0)时,继续重复执行串比较指令。一般用于计算字符串长度、定位特定字符串索引位置,或在内存中定位一串特征码
CMPSB/CMPSW/CMPSD : 对标志位的影响相当于 SUB 指令,同时还会修改寄存器 EDI 和 ESI 的值。
如果 DF 为 0,则 EDI、ESI 按指定大小递增(BYTE WORD DWORD),如果 DF 为 1,则 EDI、ESI 按指定大小递减(BYTE WORD DWORD)
REPE/REPZ 连续执行指令 : 当 ECX!=0 并且 ZF=0 时,重复执行后边的指令,每执行一次 ECX 减 1
结合使用: REPE/REPZ CMPSB 经常用于比较串是否相等 -
STOSB/STOSW/STOSD 串存储指令: 用于将串存储到指定内存地址中,相当于下面的命令
MOV BYTE PTR [EDI], AL
MOV WORD PTR [EDI], AX
MOV DWORD PTR [EDI], EAX
- 串加载指令: 用于将指定内存地址中的串加载到指定寄存器,相当于下面的命令
MOV AL, BYTE PTR [ESI]
MOV AX, WORD PTR [ESI]
MOV EAX, DWORD PTR [ESI]
- 条件置位指令
SETZ/SETE: (== 比较时)取 ZF 标志位的值保存
SETNZ/SETNE: (!= 比较时)取 ZF 标志位取反后的值保存
SETG: (> 比较时),当 ZF = 0 && SF = 0 && OF = 1 时,AL = 1
SETL: (< 比较时),当 SF = 1 || OF = 1 时,AL = 1
SETGE :(>= 比较时),语法 SETGE 操作数,操作数可以是一个字节的存储单元,也可以是一个字节宽度的寄存器。作用是当 >= 条件成立时,设定操作数值为 1,否则为 0,一般与 CMP 指令组合使用。效果等同于 JGE 指令,SF=OF 时,操作数的值则为 1
SETLE :(<= 比较时),语法 SETGE 操作数,操作数可以是一个字节的存储单元,也可以是一个字节宽度的寄存器。作用是当 <= 条件成立时,设定操作数值为 1,否则为 0,一般与 CMP 指令组合使用。效果等同于 JLE 指令,ZF=1 || SF!=OF 时,操作数的值则为 1
七、调用约定
- cdecl 调用约定
__cdecl 是 C Declaration 的缩写,规定调用 CALL 指令前,参数从右到左依次入栈。这些参数由调用者清除,因此称为手动清栈(并不是指需要在高级语言中编写清栈代码,清栈工作由编译器自动添加到程序中)
- stdcall 调用约定(API 函数调用约定)
__stdcall 是 Standard Call 的缩写,是 C++ 的标准调用方式,所有参数同样从右到左依次入栈,如果是调用类成员的话,最后一个入栈的是 this 指针。这些参数由被调用的函数在返回后清除,使用的指令是 retn xxx,xxx 表示参数占用的字节数,CPU 在执行 RET 操作后自动弹出这 xxx 字节的栈空间,因此称为自动清栈
- fastcall 调用约定
__fastcall 是编译器指定的快速调用方式,它通常规定将前两个(或若干个)参数由寄存器传递,其余参数还是通过堆栈传递,这样做是因为寄存器的传输速度远大于内存的传输速度。如果传递的参数不多,没有用到栈空间的话,也就不会有堆栈平衡的过程。不同编译器编译的程序规定的寄存器不同,返回方式和 stdcall 相同
参考
《汇编语言》(第三版) - 王爽
https://www.freebuf.com/news/others/86147.html
https://www.bilibili.com/video/av48021550?t=6518
作者: JenI 转载请注明出处,谢谢
Comments !